Plotting with matplotlib
Note
We intend to build more plotting integration with matplotlib as time goes on.
We use the standard convention for referencing the matplotlib API:
In [1701]: import matplotlib.pyplot as plt
Basic plotting: plot
See some cookbook examples for some advanced strategies
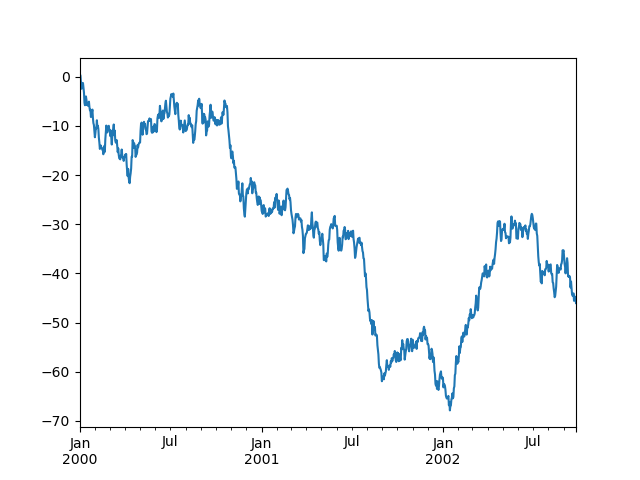
The plot method on Series and DataFrame is just a simple wrapper aroundplt.plot:
In [1702]: ts = Series(randn(1000), index=date_range('1/1/2000', periods=1000))
In [1703]: ts = ts.cumsum()
In [1704]: ts.plot()
Out[1704]: <matplotlib.axes.AxesSubplot at 0xed2aa50>
 If the index consists of dates, it calls gcf().autofmt_xdate() to try to format the x-axis nicely as per above. The method takes a number of arguments for controlling the look of the plot:
If the index consists of dates, it calls gcf().autofmt_xdate() to try to format the x-axis nicely as per above. The method takes a number of arguments for controlling the look of the plot:
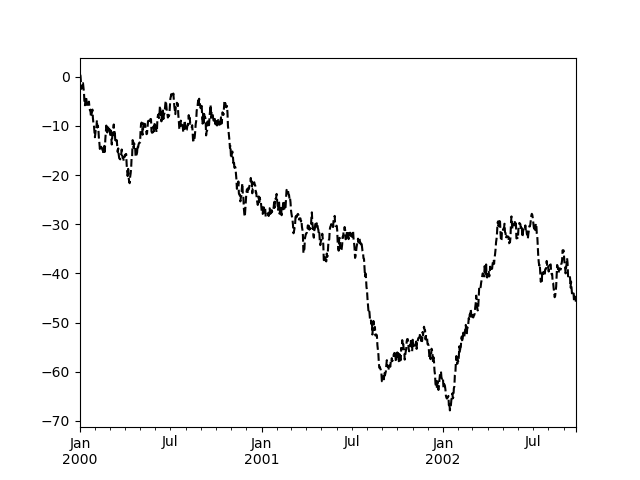
In [1705]: plt.figure(); ts.plot(style='k--', label='Series'); plt.legend() Out[1705]: <matplotlib.legend.Legend at 0xaa93bd0>
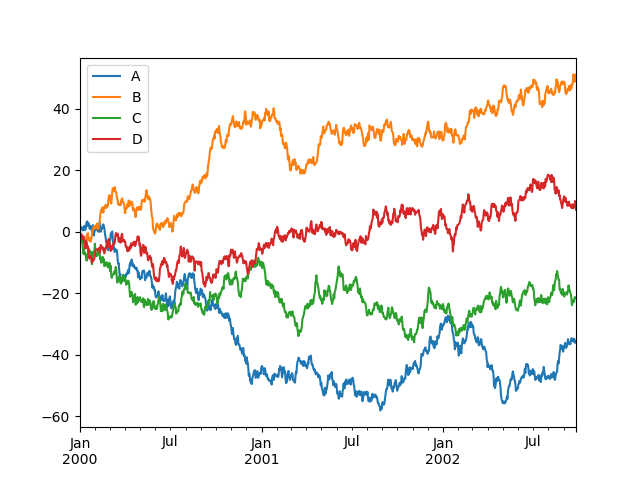
 On DataFrame, plot is a convenience to plot all of the columns with labels:
On DataFrame, plot is a convenience to plot all of the columns with labels:
In [1706]: df = DataFrame(randn(1000, 4), index=ts.index, ......: columns=['A', 'B', 'C', 'D']) ......: In [1707]: df = df.cumsum() In [1708]: plt.figure(); df.plot(); plt.legend(loc='best') Out[1708]: <matplotlib.legend.Legend at 0x98dee90>
 You may set the legend argument to False to hide the legend, which is shown by default.
You may set the legend argument to False to hide the legend, which is shown by default.
In [1709]: df.plot(legend=False) Out[1709]: <matplotlib.axes.AxesSubplot at 0x86de210>
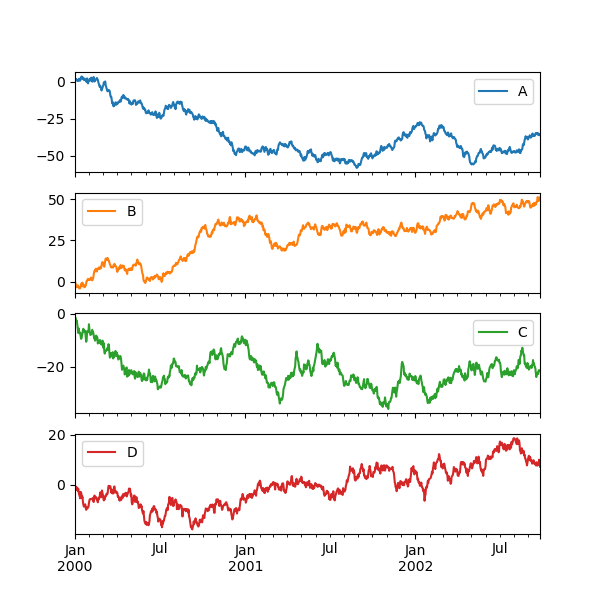
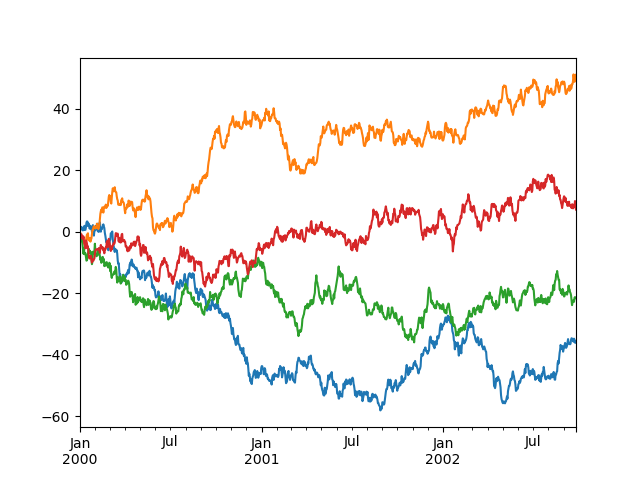 Some other options are available, like plotting each Series on a different axis:
Some other options are available, like plotting each Series on a different axis:
In [1710]: df.plot(subplots=True, figsize=(8, 8)); plt.legend(loc='best') Out[1710]: <matplotlib.legend.Legend at 0x79e7b90>
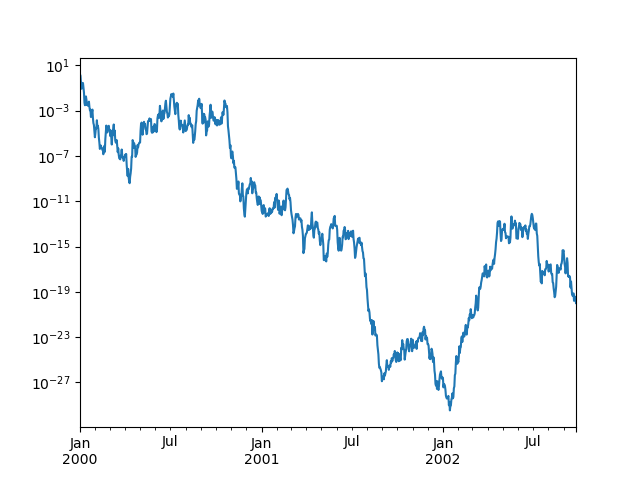
 You may pass logy to get a log-scale Y axis.
You may pass logy to get a log-scale Y axis.
In [1711]: plt.figure();
In [1711]: ts = Series(randn(1000), index=date_range('1/1/2000', periods=1000))
In [1712]: ts = np.exp(ts.cumsum())
In [1713]: ts.plot(logy=True)
Out[1713]: <matplotlib.axes.AxesSubplot at 0x79e7190>
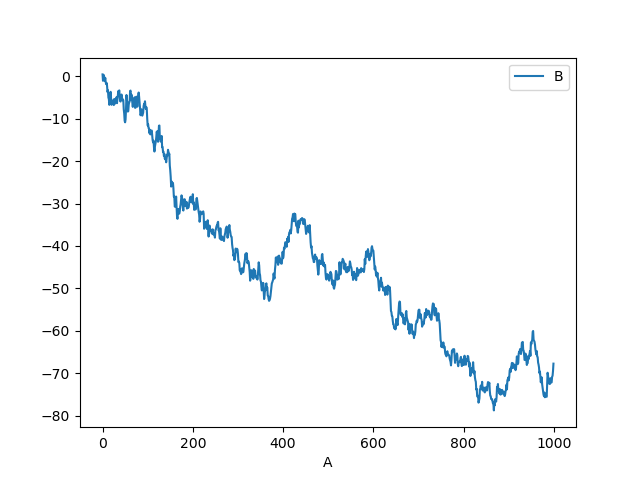
 You can plot one column versus another using the x and y keywords in DataFrame.plot:
You can plot one column versus another using the x and y keywords in DataFrame.plot:
In [1714]: plt.figure() Out[1714]: <matplotlib.figure.Figure at 0x582ed10> In [1715]: df3 = DataFrame(np.random.randn(1000, 2), columns=['B', 'C']).cumsum() In [1716]: df3['A'] = Series(range(len(df))) In [1717]: df3.plot(x='A', y='B') Out[1717]: <matplotlib.axes.AxesSubplot at 0x583db90>
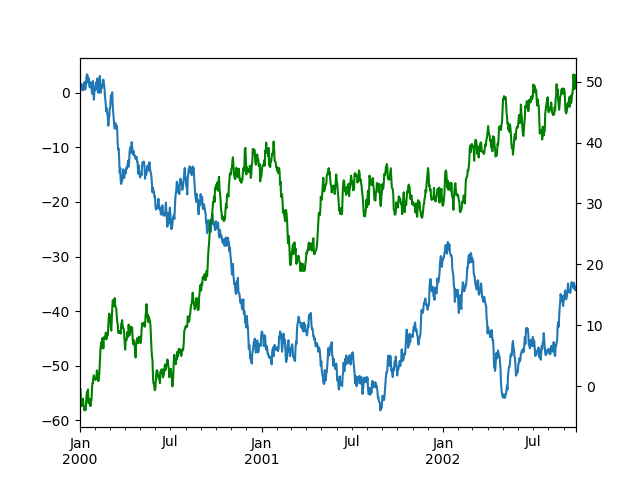
Plotting on a Secondary Y-axis
To plot data on a secondary y-axis, use the secondary_y keyword:
In [1718]: plt.figure() Out[1718]: <matplotlib.figure.Figure at 0x5c02f90> In [1719]: df.A.plot() Out[1719]: <matplotlib.axes.AxesSubplot at 0xed2c0d0> In [1720]: df.B.plot(secondary_y=True, style='g') Out[1720]: <matplotlib.axes.AxesSubplot at 0xed2c0d0>
Selective Plotting on Secondary Y-axis
To plot some columns in a DataFrame, give the column names to the secondary_y keyword:
In [1721]: plt.figure()
Out[1721]: <matplotlib.figure.Figure at 0x8998b10>
In [1722]: ax = df.plot(secondary_y=['A', 'B'])
In [1723]: ax.set_ylabel('CD scale')
Out[1723]: <matplotlib.text.Text at 0xed60610>
In [1724]: ax.right_ax.set_ylabel('AB scale')
Out[1724]: <matplotlib.text.Text at 0x58aa7d0>
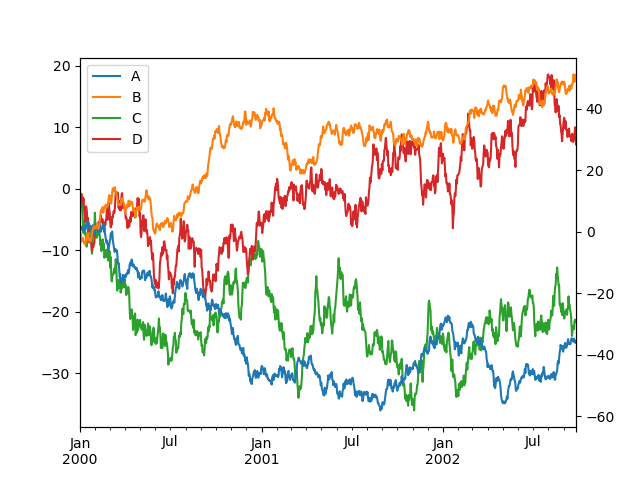
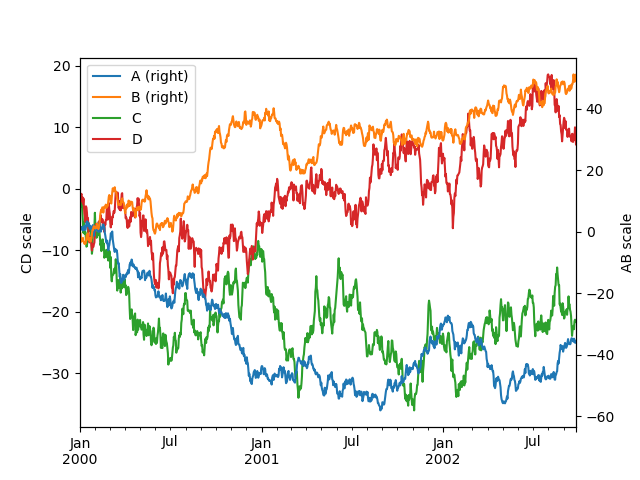 Note that the columns plotted on the secondary y-axis is automatically marked with “(right)” in the legend. To turn off the automatic marking, use the mark_right=False keyword:
Note that the columns plotted on the secondary y-axis is automatically marked with “(right)” in the legend. To turn off the automatic marking, use the mark_right=False keyword:
In [1725]: plt.figure() Out[1725]: <matplotlib.figure.Figure at 0x79fee90> In [1726]: df.plot(secondary_y=['A', 'B'], mark_right=False) Out[1726]: <matplotlib.axes.AxesSubplot at 0x8800990>
Suppressing tick resolution adjustment
Pandas includes automatically tick resolution adjustment for regular frequency time-series data. For limited cases where pandas cannot infer the frequency information (e.g., in an externally created twinx), you can choose to suppress this behavior for alignment purposes.
Here is the default behavior, notice how the x-axis tick labelling is performed:
In [1727]: plt.figure() Out[1727]: <matplotlib.figure.Figure at 0x79f6590> In [1728]: df.A.plot() Out[1728]: <matplotlib.axes.AxesSubplot at 0x86d65d0>
 Using the x_compat parameter, you can suppress this bevahior:
Using the x_compat parameter, you can suppress this bevahior:
In [1729]: plt.figure() Out[1729]: <matplotlib.figure.Figure at 0x8700290> In [1730]: df.A.plot(x_compat=True) Out[1730]: <matplotlib.axes.AxesSubplot at 0x86cb210>
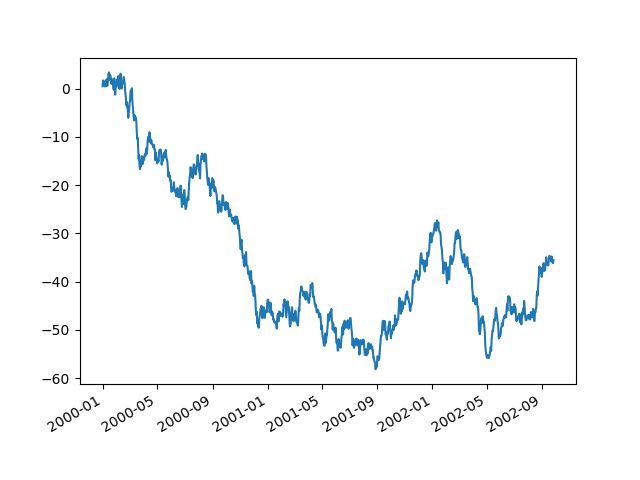 If you have more than one plot that needs to be suppressed, the use method inpandas.plot_params can be used in a with statement:
If you have more than one plot that needs to be suppressed, the use method inpandas.plot_params can be used in a with statement:
In [1731]: import pandas as pd
In [1732]: plt.figure()
Out[1732]: <matplotlib.figure.Figure at 0x6667e10>
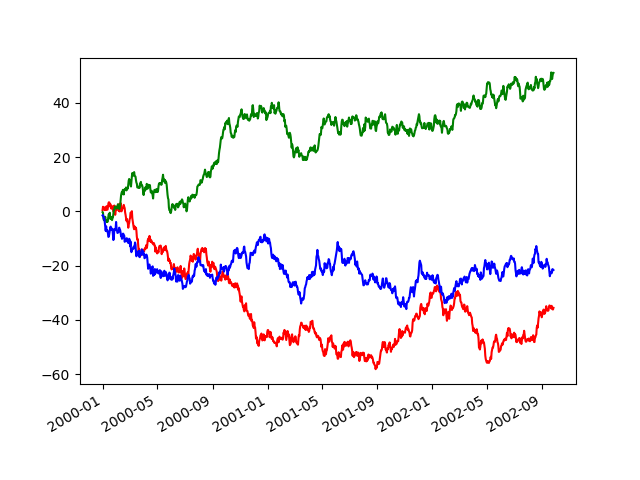
In [1733]: with pd.plot_params.use('x_compat', True):
......: df.A.plot(color='r')
......: df.B.plot(color='g')
......: df.C.plot(color='b')
......:
Targeting different subplots
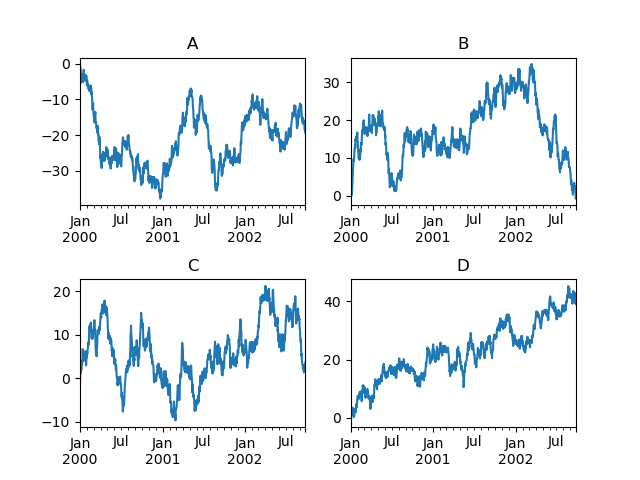
You can pass an ax argument to Series.plot to plot on a particular axis:
In [1734]: fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
In [1735]: df['A'].plot(ax=axes[0,0]); axes[0,0].set_title('A')
Out[1735]: <matplotlib.text.Text at 0xa22ca90>
In [1736]: df['B'].plot(ax=axes[0,1]); axes[0,1].set_title('B')
Out[1736]: <matplotlib.text.Text at 0xa253090>
In [1737]: df['C'].plot(ax=axes[1,0]); axes[1,0].set_title('C')
Out[1737]: <matplotlib.text.Text at 0xa2a2490>
In [1738]: df['D'].plot(ax=axes[1,1]); axes[1,1].set_title('D')
Out[1738]: <matplotlib.text.Text at 0xa2854d0>
Other plotting features
Bar plots
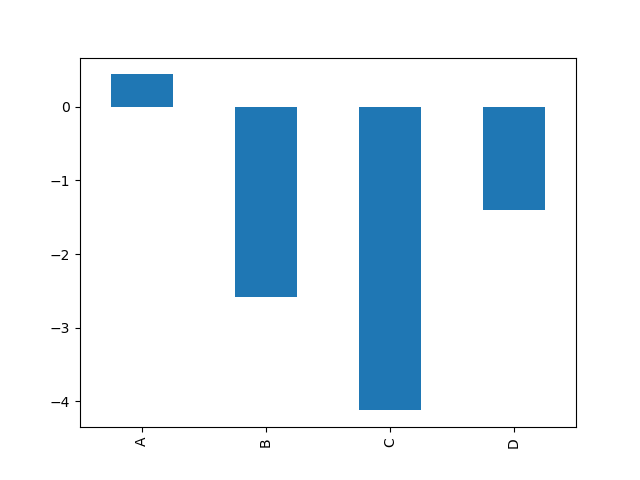
For labeled, non-time series data, you may wish to produce a bar plot:
In [1739]: plt.figure(); In [1739]: df.ix[5].plot(kind='bar'); plt.axhline(0, color='k') Out[1739]: <matplotlib.lines.Line2D at 0x11d83e10>
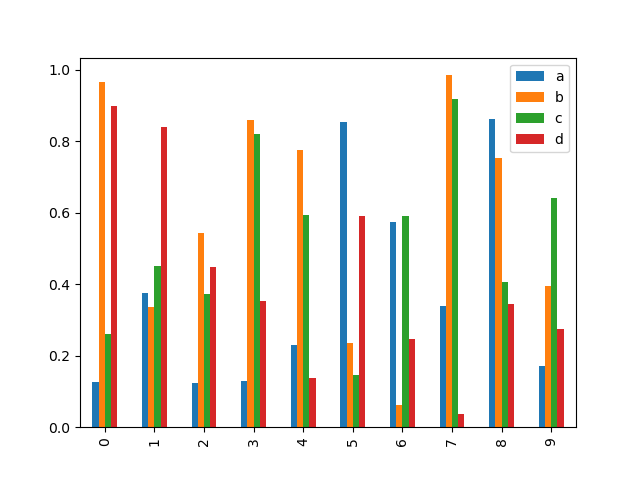
 Calling a DataFrame’s plot method with kind='bar' produces a multiple bar plot:
Calling a DataFrame’s plot method with kind='bar' produces a multiple bar plot:
In [1740]: df2 = DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd']) In [1741]: df2.plot(kind='bar');
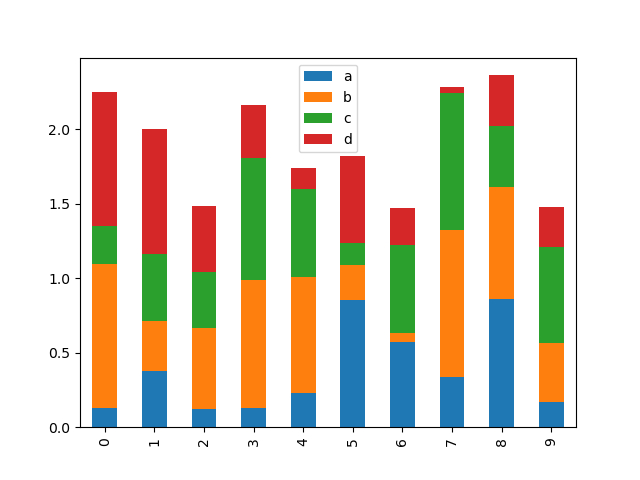
 To produce a stacked bar plot, pass stacked=True:
To produce a stacked bar plot, pass stacked=True:
In [1741]: df2.plot(kind='bar', stacked=True);
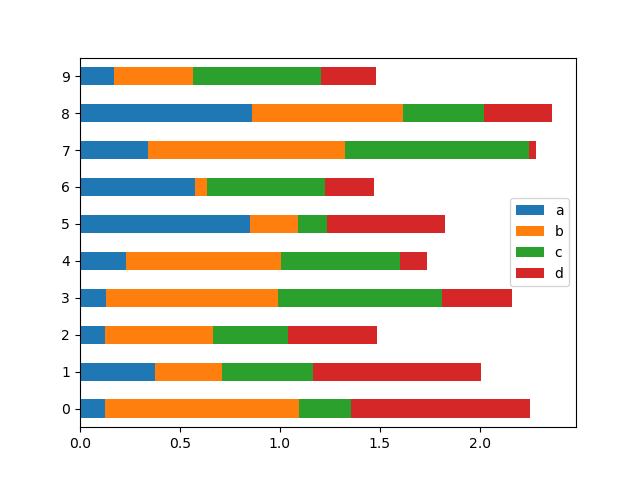
 To get horizontal bar plots, pass kind='barh':
To get horizontal bar plots, pass kind='barh':
In [1741]: df2.plot(kind='barh', stacked=True);
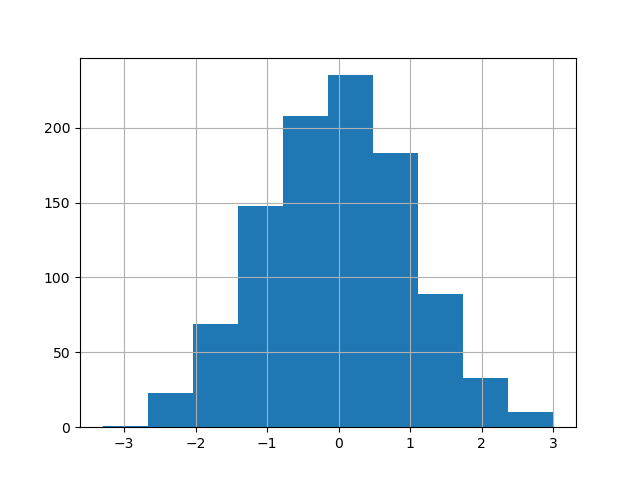
Histograms
In [1741]: plt.figure(); In [1741]: df['A'].diff().hist() Out[1741]: <matplotlib.axes.AxesSubplot at 0x1150b1d0>
 For a DataFrame, hist plots the histograms of the columns on multiple subplots:
For a DataFrame, hist plots the histograms of the columns on multiple subplots:
In [1742]: plt.figure()
Out[1742]: <matplotlib.figure.Figure at 0x12cfba90>
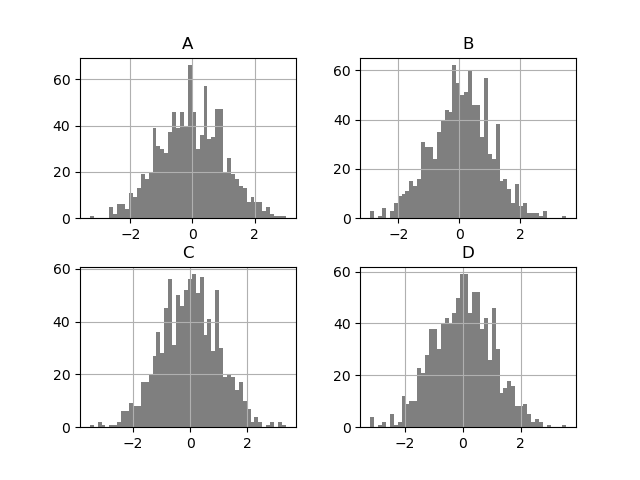
In [1743]: df.diff().hist(color='k', alpha=0.5, bins=50)
Out[1743]:
array([[Axes(0.125,0.552174;0.336957x0.347826),
Axes(0.563043,0.552174;0.336957x0.347826)],
[Axes(0.125,0.1;0.336957x0.347826),
Axes(0.563043,0.1;0.336957x0.347826)]], dtype=object)
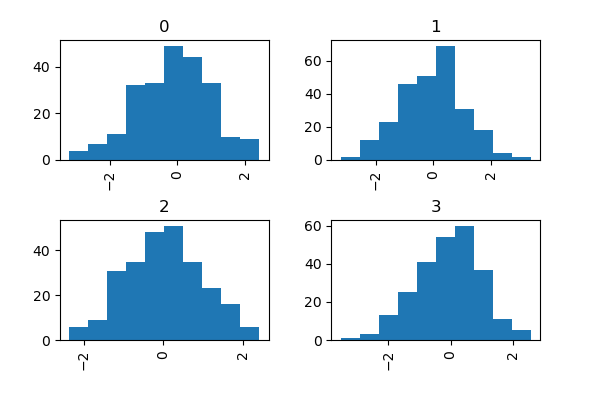
 New since 0.10.0, the by keyword can be specified to plot grouped histograms:
New since 0.10.0, the by keyword can be specified to plot grouped histograms:
In [1744]: data = Series(np.random.randn(1000))
In [1745]: data.hist(by=np.random.randint(0, 4, 1000))
Out[1745]:
array([[Axes(0.1,0.6;0.347826x0.3), Axes(0.552174,0.6;0.347826x0.3)],
[Axes(0.1,0.15;0.347826x0.3), Axes(0.552174,0.15;0.347826x0.3)]], dtype=object)
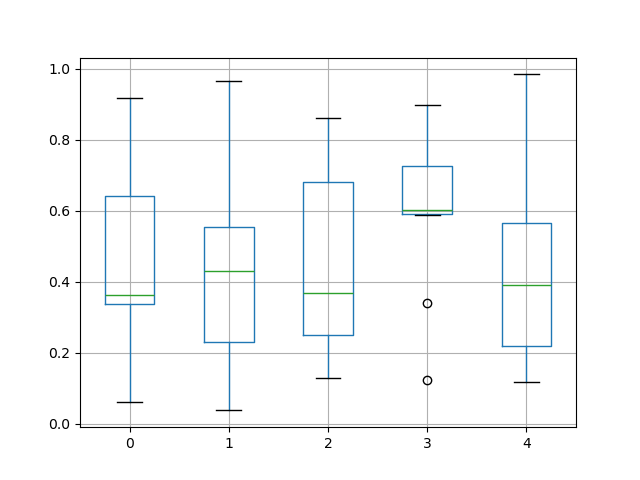
Box-Plotting
DataFrame has a boxplot method which allows you to visualize the distribution of values within each column.
For instance, here is a boxplot representing five trials of 10 observations of a uniform random variable on [0,1).
In [1746]: df = DataFrame(np.random.rand(10,5)) In [1747]: plt.figure(); In [1747]: bp = df.boxplot()
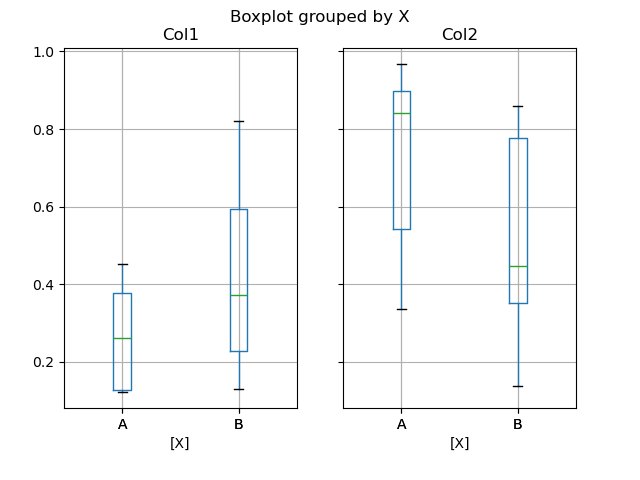
 You can create a stratified boxplot using the by keyword argument to create groupings. For instance,
You can create a stratified boxplot using the by keyword argument to create groupings. For instance,
In [1748]: df = DataFrame(np.random.rand(10,2), columns=['Col1', 'Col2'] ) In [1749]: df['X'] = Series(['A','A','A','A','A','B','B','B','B','B']) In [1750]: plt.figure(); In [1750]: bp = df.boxplot(by='X')
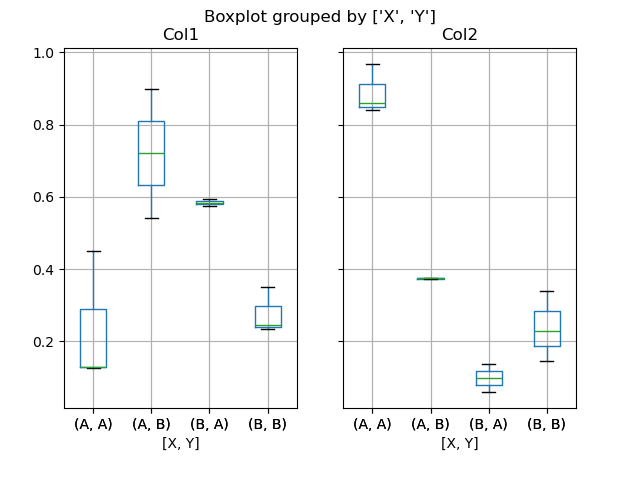
 You can also pass a subset of columns to plot, as well as group by multiple columns:
You can also pass a subset of columns to plot, as well as group by multiple columns:
In [1751]: df = DataFrame(np.random.rand(10,3), columns=['Col1', 'Col2', 'Col3']) In [1752]: df['X'] = Series(['A','A','A','A','A','B','B','B','B','B']) In [1753]: df['Y'] = Series(['A','B','A','B','A','B','A','B','A','B']) In [1754]: plt.figure(); In [1754]: bp = df.boxplot(column=['Col1','Col2'], by=['X','Y'])
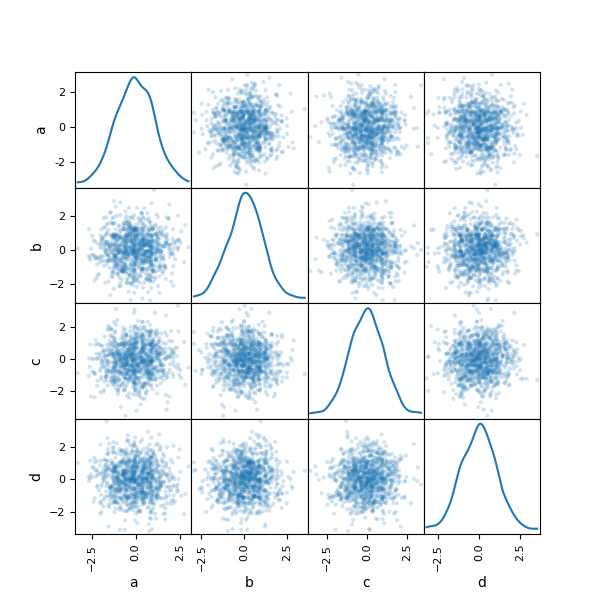
Scatter plot matrix
- New in 0.7.3. You can create a scatter plot matrix using the
- scatter_matrix method in pandas.tools.plotting:
In [1755]: from pandas.tools.plotting import scatter_matrix
In [1756]: df = DataFrame(np.random.randn(1000, 4), columns=['a', 'b', 'c', 'd'])
In [1757]: scatter_matrix(df, alpha=0.2, figsize=(8, 8), diagonal='kde')
Out[1757]:
array([[Axes(0.125,0.7;0.19375x0.2), Axes(0.31875,0.7;0.19375x0.2),
Axes(0.5125,0.7;0.19375x0.2), Axes(0.70625,0.7;0.19375x0.2)],
[Axes(0.125,0.5;0.19375x0.2), Axes(0.31875,0.5;0.19375x0.2),
Axes(0.5125,0.5;0.19375x0.2), Axes(0.70625,0.5;0.19375x0.2)],
[Axes(0.125,0.3;0.19375x0.2), Axes(0.31875,0.3;0.19375x0.2),
Axes(0.5125,0.3;0.19375x0.2), Axes(0.70625,0.3;0.19375x0.2)],
[Axes(0.125,0.1;0.19375x0.2), Axes(0.31875,0.1;0.19375x0.2),
Axes(0.5125,0.1;0.19375x0.2), Axes(0.70625,0.1;0.19375x0.2)]], dtype=object)
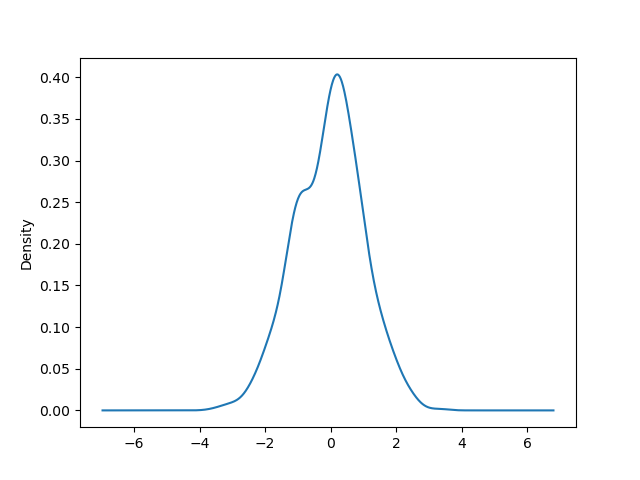
New in 0.8.0 You can create density plots using the Series/DataFrame.plot and settingkind=’kde’:
In [1758]: ser = Series(np.random.randn(1000)) In [1759]: ser.plot(kind='kde') Out[1759]: <matplotlib.axes.AxesSubplot at 0x1567a0d0>
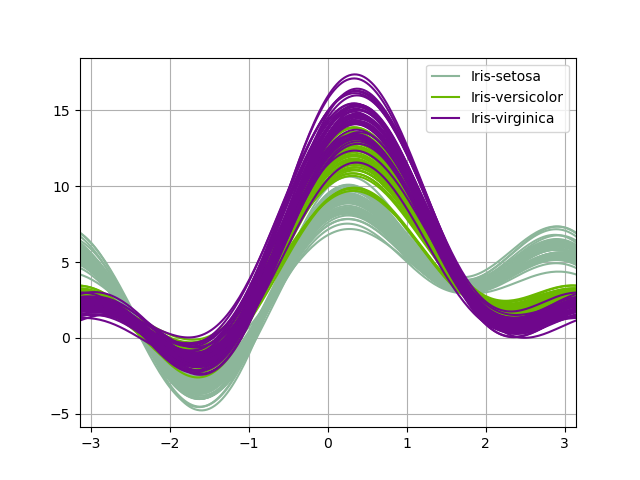
Andrews Curves
Andrews curves allow one to plot multivariate data as a large number of curves that are created using the attributes of samples as coefficients for Fourier series. By coloring these curves differently for each class it is possible to visualize data clustering. Curves belonging to samples of the same class will usually be closer together and form larger structures.
Note: The “Iris” dataset is available here.
In [1760]: from pandas import read_csv
In [1761]: from pandas.tools.plotting import andrews_curves
In [1762]: data = read_csv('data/iris.data')
In [1763]: plt.figure()
Out[1763]: <matplotlib.figure.Figure at 0x1567a090>
In [1764]: andrews_curves(data, 'Name')
Out[1764]: <matplotlib.axes.AxesSubplot at 0x16e1de50>
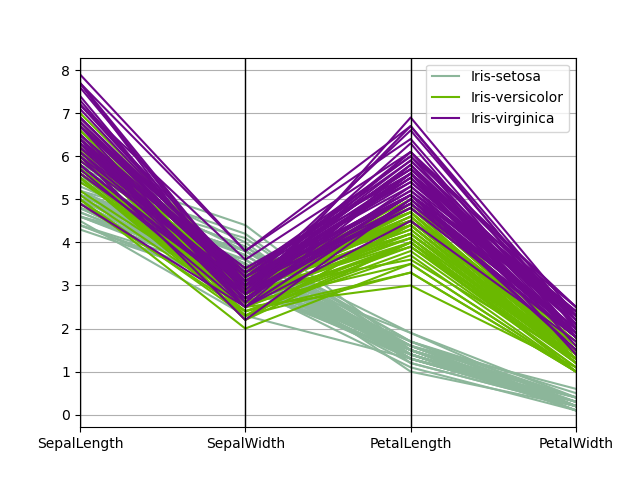
Parallel Coordinates
Parallel coordinates is a plotting technique for plotting multivariate data. It allows one to see clusters in data and to estimate other statistics visually. Using parallel coordinates points are represented as connected line segments. Each vertical line represents one attribute. One set of connected line segments represents one data point. Points that tend to cluster will appear closer together.
In [1765]: from pandas import read_csv
In [1766]: from pandas.tools.plotting import parallel_coordinates
In [1767]: data = read_csv('data/iris.data')
In [1768]: plt.figure()
Out[1768]: <matplotlib.figure.Figure at 0x177e4f10>
In [1769]: parallel_coordinates(data, 'Name')
Out[1769]: <matplotlib.axes.AxesSubplot at 0x177f0210>
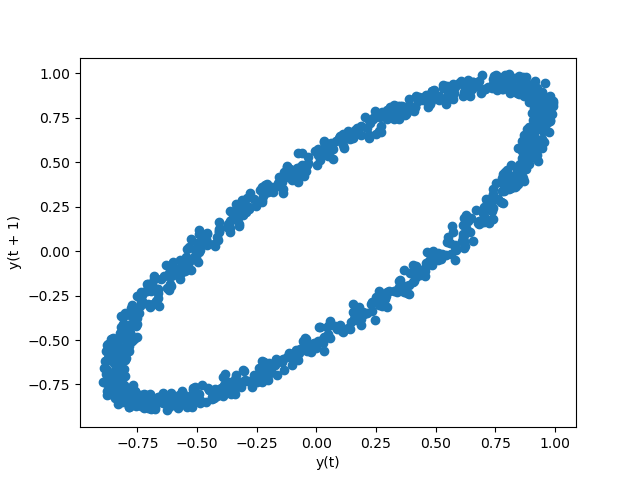
Lag Plot
Lag plots are used to check if a data set or time series is random. Random data should not exhibit any structure in the lag plot. Non-random structure implies that the underlying data are not random.
In [1770]: from pandas.tools.plotting import lag_plot In [1771]: plt.figure() Out[1771]: <matplotlib.figure.Figure at 0x177ee7d0> In [1772]: data = Series(0.1 * np.random.random(1000) + ......: 0.9 * np.sin(np.linspace(-99 * np.pi, 99 * np.pi, num=1000))) ......: In [1773]: lag_plot(data) Out[1773]: <matplotlib.axes.AxesSubplot at 0x18317c90>
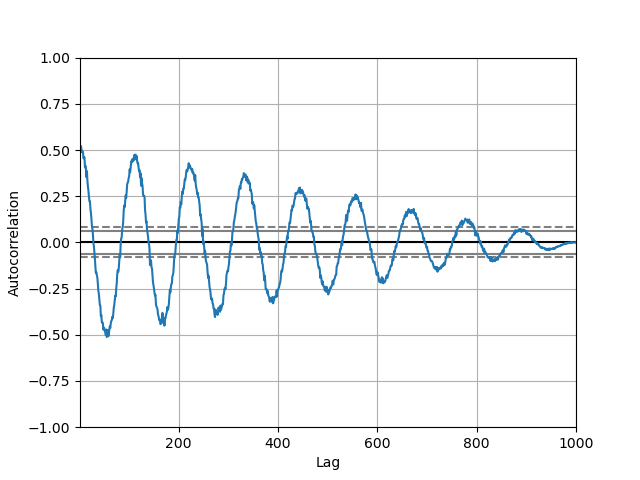
Autocorrelation Plot
Autocorrelation plots are often used for checking randomness in time series. This is done by computing autocorrelations for data values at varying time lags. If time series is random, such autocorrelations should be near zero for any and all time-lag separations. If time series is non-random then one or more of the autocorrelations will be significantly non-zero. The horizontal lines displayed in the plot correspond to 95% and 99% confidence bands. The dashed line is 99% confidence band.
In [1774]: from pandas.tools.plotting import autocorrelation_plot In [1775]: plt.figure() Out[1775]: <matplotlib.figure.Figure at 0x18173750> In [1776]: data = Series(0.7 * np.random.random(1000) + ......: 0.3 * np.sin(np.linspace(-9 * np.pi, 9 * np.pi, num=1000))) ......: In [1777]: autocorrelation_plot(data) Out[1777]: <matplotlib.axes.AxesSubplot at 0x183130d0>
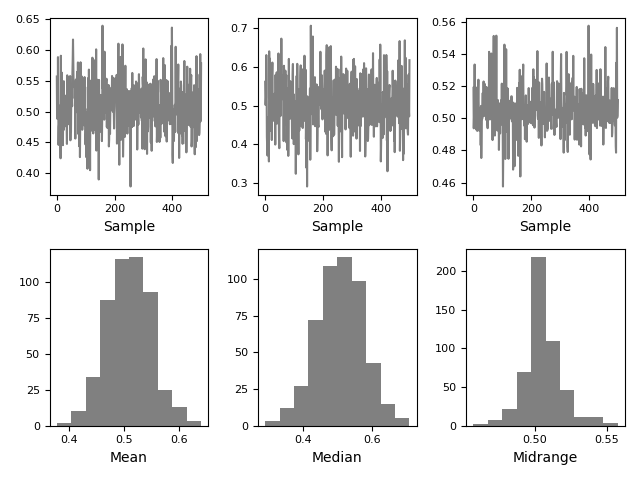
Bootstrap Plot
Bootstrap plots are used to visually assess the uncertainty of a statistic, such as mean, median, midrange, etc. A random subset of a specified size is selected from a data set, the statistic in question is computed for this subset and the process is repeated a specified number of times. Resulting plots and histograms are what constitutes the bootstrap plot.
In [1778]: from pandas.tools.plotting import bootstrap_plot In [1779]: data = Series(np.random.random(1000)) In [1780]: bootstrap_plot(data, size=50, samples=500, color='grey') Out[1780]: <matplotlib.figure.Figure at 0x1861f5d0>
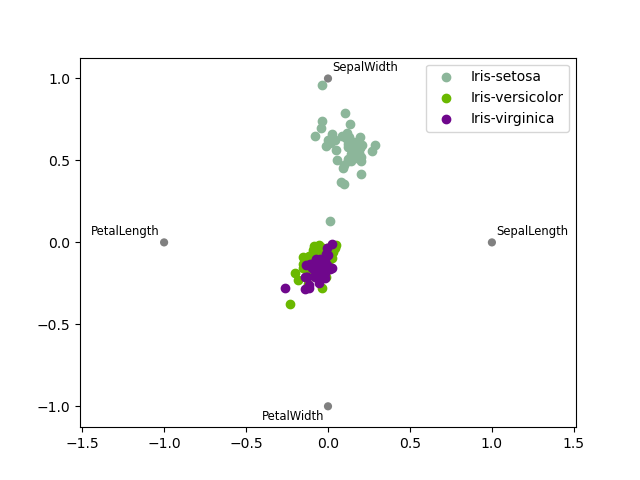
RadViz
RadViz is a way of visualizing multi-variate data. It is based on a simple spring tension minimization algorithm. Basically you set up a bunch of points in a plane. In our case they are equally spaced on a unit circle. Each point represents a single attribute. You then pretend that each sample in the data set is attached to each of these points by a spring, the stiffness of which is proportional to the numerical value of that attribute (they are normalized to unit interval). The point in the plane, where our sample settles to (where the forces acting on our sample are at an equilibrium) is where a dot representing our sample will be drawn. Depending on which class that sample belongs it will be colored differently.
Note: The “Iris” dataset is available here.
In [1781]: from pandas import read_csv
In [1782]: from pandas.tools.plotting import radviz
In [1783]: data = read_csv('data/iris.data')
In [1784]: plt.figure()
Out[1784]: <matplotlib.figure.Figure at 0x183179d0>
In [1785]: radviz(data, 'Name')
Out[1785]: <matplotlib.axes.AxesSubplot at 0x19652150>